[dev.icinga.com #11932] many check commands executed at same time when master reload #4277
Comments
|
Updated by cstein on 2016-07-19 11:08:30 +00:00 I had a similar issue with a 2 node cluster. My virtual machines encountered a problem and had to reboot them. Once done, I tried to start the Icinga 2 daemon which failed because of an invalid icinga2.state file (caused by the VM crash). Once I removed the broken icinga2.state file and tried to start the Icinga 2 daemon, everything went as expected. The only problem was that all checks assigned to the Icinga 2 node were executed immediately, causing the VM to receive a pretty high load and memory usage. After a while this changed but the first minutes the system was unusable. On the top process you were able to see that plenty of checks were executed at the same time. The first cluster node was working fine and executing checks - only the second instance didn't work. Now I'm unable to reproduce this issue. |
|
Updated by gbeutner on 2016-08-08 09:19:56 +00:00
Please re-test this with the latest snapshot. |
|
Updated by stideswell on 2016-08-12 23:34:13 +00:00 Hello Gunnar I am experiencing the self-same issue. I'm running Icinga r2.4.10-1 on Ubuntu 16.04. I have a two node cluster and one node does the most of the checking (because the zone it serves has the bulk of the hosts). It runs a pretty expensive plugin (check_nwc_health from labs.consol.de). I cannot have too many instances of the checker running because I run into OOM killer issues (which usually kills Icinga itself). So for that reason I upgraded to the current version so that I can add concurrent_checks = 50 to my checker.conf. But I've encountered many instances where if I start Icinga2 on the main checking node that the number of instances of host and service check increases beyond 400 and totally smashes the host (until OOM killer eventually kills Icinga2). In my latest test I removed the icinga2.state file and the behaviour returned to acceptable (i.e. not running more than 50 checks simultaneously). As a long time Nagios user I really love the way Icinga2 defines check commands and service checks. It removes much of the irritation that I've previously experienced with Nagios over the years. But the way that icinga2 runs a bit out of control and is eventually killed is giving me serious concerns about replacing one of my Nagios instances with Icinga2. This particular behaviour (of not throttling the number of checks it attempts to execute simultaneously) is a real "deal-breaker". I'd like to see the concurrent_checks behaviour be applied very robustly so that there are no instances where Icinga2 can apparently ignore this setting (to its own detriment). I'm happy to supply whatever debug information you require in order to get this issue resolved. |
|
Updated by jyoung15 on 2016-08-18 12:37:26 +00:00
I am experiencing the same issue as well. I set up a minimal configuration to reproduce this based on the test in #8137. The number of concurrent checks exceeds concurrent_checks. As you can see below there were 185 instances of sleep even though it should not exceed 35. One thing I noticed in the log output it shows the check finished in less than 30 seconds (based on the log timestamps), which should be impossible. Maybe icinga2 isn't properly detecting when a check exits? I have attached the initial logs for reference. Using v2.4.10-702-ge5566a6 on Linux Gentoo x86_64. |
|
Updated by jyoung15 on 2016-08-19 03:51:58 +00:00
The attached patch is a kludge, but it resolves the problem for me. I believe the problem is that calls to Checkable::*PendingChecks do not take into account items added to the ThreadPool::Queue that have not executed yet. The patch adds a wrapper class around std::deque in ThreadPool which increases or decreases PendingChecks when items are added/removed. I had to separate Checkable::*PendingChecks into a new class (PendingChecks) due to a circular dependency issue. In my testing so far, this keeps the number of concurrent checks at or below the concurrent_checks setting. Please note, this patch has not been tested thoroughly and may not follow the coding standards. It could quite possibly introduce new bugs. I just wanted to provide it as an example of a possible solution. I'm sure you guys can do a much better job than I can. |
|
Updated by stideswell on 2016-08-24 00:07:17 +00:00 Hello I haven't applied the patch on my test lab system at this stage. I have continued to be afflicted by this issue. Even removing the /var/lib/icinga2/icinga2.state file doesn't really guarantee that when icinga2 is restarted (after being killed by OOM) that it won't run totally out of control and start more check commands than are good for its own well-being. I did read through the online documentation looking for inspiration though, as I feel I must be doing something wrong. There are very large installations running distributed Icinga, and if they were having issues this would be a big deal to Icinga's dev team, and it doesn't seem to be. What I found in the documentation was the following section http://docs.icinga.org/icinga2/latest/doc/module/icinga2/toc\#!/icinga2/latest/doc/module/icinga2/chapter/distributed-monitoring#distributed-monitoring-top-down-config-sync. I think in the instance when you are synchronising the configuration to the satellite node and the satellite node is running its own scheduler instance that you should not set accept_commands = true in /etc/icinga2/features-available/api.conf. Setting it to true would presumably lead to commands being pushed from the parent zone to the child zone perhaps with no reference to what workload the satellite endpoint's scheduler is already undertaking. I'm trying this out but I'm pretty certain (call it a gut feeling) that I'm on to something. The documentation is, in my opinion, not very clear on this aspect and, if I'm right about this, it should be corrected as it gives a false impression of a problem with the product when it's just a configuration error and the fault lies with me. |
|
Updated by jyoung15 on 2016-08-26 02:28:08 +00:00
I will be interested if your theory is correct. As mentioned in #11932#note-4 I was able to reproduce the issue with a minimal configuration (no distributed monitoring, zones, etc). It seems there was a regression in #8137 (actually I'm not sure if concurrent_checks ever worked properly). I had to update my patch due to the recent -fvisibility=hidden changes. Attached is an updated version if you're interested. |
|
Updated by stideswell on 2016-08-27 06:51:15 +00:00 Hello jyoung15 I must confess that I did not read through the details of your test case (which doesn't involve clustering) so it's clear my "gut feeling" was wrong I guess. In any case despite my early optimism the system failed for exactly the same reason as always (OOM Killer) some time (a few days) after my post. What concerns me about all of this is that I also see there are some known issues that prevent having more than 2 endpoints in a cluster zone. So I cannot even mitigate against this issue by bunging a lot more nodes on. I wonder if anyone in the Icinga development team is aware of how serious this issue is? At the moment I've got kludgy scripts to apply oom_score_adj values to each Icinga2 instance just to prevent it from being killed but I'm feeling nervous about implementing Icinga2 now given the stability problems I'm seeing. I cannot see any reference to these issues in the change log for v2.5.3 so I'm not hopeful that putting on the latest code will assist me. I'm starting to think I might be better off using Icinga2 with Gearman so that at least I can increase the number of nodes servicing a zone? I haven't ruled out using your patch given that you appear to be getting some success with it. |
|
Updated by gbeutner on 2016-08-29 11:01:51 +00:00
jyoung15: Your problem analysis is spot on. m_PendingChecks needs to be increased before the task is enqueued. I'll see if I can come up with a cleaner patch. :) |
|
Updated by gbeutner on 2016-08-29 12:13:33 +00:00 3d14905 should fix this. Please test the patch. :) |
|
Updated by gbeutner on 2016-08-29 12:15:03 +00:00
Applied in changeset 3d14905. |
|
Updated by stideswell on 2016-08-30 07:14:31 +00:00 Hello Gunnar/Jyoung15 I've been testing the patch today and it looks very promising. A freshly compiled Icinga2 instance ran into the exactly the same problems as I have seen before with the Icinga-built binaries. I did this multiple times and the result was quite consistent - after a few minutes of restarting Icinga2 the whole box is smashed by hundreds of service checks and OOM-killer starts off. In some instances the host was so unhealthy I had to do a power reset because it was totally unresponsive. With the patch applied to libchecker.so on the host that does all the host/service checks the behaviour is much more predictable. It appears to be respecting the concurrent_checks limit I've set. I really appreciate that you appear to have resolved the issue. I will test this out for a few weeks on a heavily loaded and poorly resourced VM and let you know how I go. I'm eagerly awaiting version 2.5.4 as a package, so that I can deploy it to the production servers. I hate to be negative, because I really like Icinga2, and I believe Icinga2 has some fantastic improvements over Nagios which can be painful to configure. But it is a bit concerning that such a massive stability issue appears to have crept into a package that sysadmins are blithely dragging down and deploying on their systems. Yes Nagios is painful sometimes, but always very reliable. Anyway, apologies for any negative remarks - I only say it because I think Icinga2 is so excellent and stuff like this "takes the gloss off it" somewhat. Thanks to you both for providing a patch for this issue. |
|
Updated by mnardin on 2016-08-30 10:24:27 +00:00 Hi, We have to revert to 2.4.10 hence every restart/deployment will trigger this kind of load problem. I second stideswell opinion completely: Keep up the good work |

|
Updated by mfriedrich on 2016-08-30 12:27:49 +00:00
|
|
Updated by stideswell on 2016-08-30 16:40:05 +00:00 By the way, it's hard to say for sure, but I originally deployed v2.4.1-2 (the package version that comes with Ubuntu 16). I'm pretty sure that these issues with running all the checks at once and smashing the Icinga server (OOM-killer etc) were occurring then? That's why I went out looking for a max_concurrent_checks type parameter and landed on v2.4.10. So I suspect stability may have been a factor for quite a while? It's hard to remember now as I've been fiddling with icinga2 (on and off) for a few weeks now? The system I run is tiny (hosts=370, services=1900) but it's running on a few low-spec VM's. I thought there were big Icinga installations out there (many thousands of hosts)? But maybe some of the bigger guys are still using icinga1 (essentially just Nagios)? My test lab, with the patch, remains very busy, but essentially properly throttled by concurrent_checks and that's making me feel more confident about replacing Nagios with Icinga2. |
|
Updated by tclh123 on 2016-08-31 09:47:40 +00:00 I upgrade my icinga cluster from 2.4.10 to 2.5.4, and set concurrent_checks = 128. Now the loads of my checker nodes are fine. |
|
Updated by stideswell on 2016-08-31 20:56:48 +00:00 Wow, that's a very quick turnaround. Thanks to the Icinga team. I will try it out early next week. Incidentally, to the Icinga team, it would be really helpful if old package versions were made available under an archives directory of the web site. I had my pre-production servers on 2.4.10-1 and wanted to add another server and yet the only package available (at that time) was 2.5.3-1 (I'm using the Ubuntu repository). If older packages were available we could fix (i.e. pin or prevent the version number being changed) the version at our end, or revert quickly if we've moved to a problematic version. You'd only need to keep major "dot versions" going back 5 or so versions. Doing this would really help people using the software in production environments. |
|
Updated by mfriedrich on 2016-09-01 07:40:51 +00:00 Agreed. The underlying issue is that the PPA does not keep old versions and we're currently just mirroring that repository on p.i.o. We will discuss and consider changing that in the future for our own build system. |
|
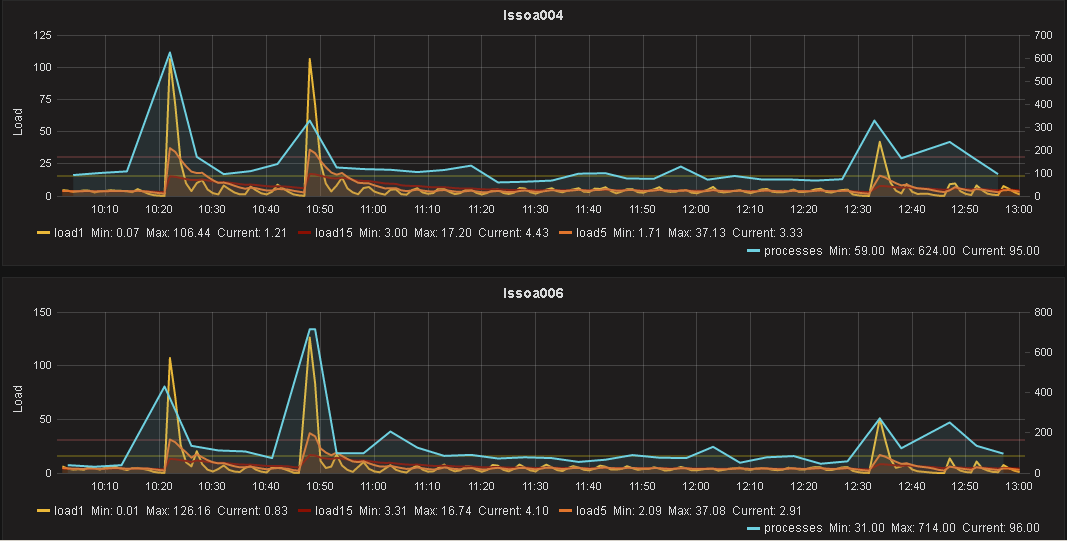
Updated by ricardo on 2016-09-01 11:08:07 +00:00
Hi, had the same issue again after installing Icinga >2.5. Today I installed 2.5.4 and it looks muuuch better now. Our environment has ~1000 Hosts and ~20000 Services The 2 peaks on the left side are reloads with icinga 2.5.3 and "concurrent_checks" set to 200. The peak close after 12:30 was the reload with 2.5.4 and same setting for concurrent_checks. Then I changed teh value to 100 and did another reload at around 12:45. Thanks again for this fix. |
This issue has been migrated from Redmine: https://dev.icinga.com/issues/11932
Created by tclh123 on 2016-06-13 08:04:04 +00:00
Assignee: gbeutner
Status: Resolved (closed on 2016-08-29 12:15:03 +00:00)
Target Version: 2.5.4
Last Update: 2016-09-01 11:08:07 +00:00 (in Redmine)
I just upgraded my icinga from 2.4.2 to 2.4.10, and I found there're many check commands executed at same time on my checker nodes every 10 minutes. You can check the screen shot I uploaded.
I post my custom config package use icinga2 api every 10 minutes, which cause icinga master to reload, and the time interval is exactly the same with the many check commands on my checker nodes.
So can you confirm it is a bug which brought by my icinga upgrading?
Thank you very much!
Attachments
Changesets
2016-08-29 12:12:29 +00:00 by gbeutner 3d14905
2016-08-30 11:58:39 +00:00 by gbeutner 8f7b819
The text was updated successfully, but these errors were encountered: